
productgovernance.substack.com /feed
Compliance Left Shifted - We explore how teams shift compliance left.
RSS Feed
productgovernance.substack.com /feed
Compliance Left Shifted - We explore how teams shift compliance left.
RSS Feed

Many of us are familiar with the concept of policy as code. Tools like OPA Gatekeeper, Kyverno, and HashiCorp Sentinel let us define and enforce policies programmatically. They promise automation, consistency, and direct integration into development pipelines, effectively shifting security left. When I worked on DoD Platform One, we used Gatekeeper to implement many NIST SP 800-53 AC - Access Controls on our infrastructure. But we faced a challenge: we couldn’t effectively create and enforce policies over the entire process.
This article kicks off a series titled "Compliance as Code," where I’ll explore how to shift compliance left using tools like Hadolint and Witness. This first entry will focus on mapping Hadolint to NIST SP 800-53 controls and enforcing those rules with Witness policies. We’ll also dive into how NIST SP 800-204D provides technical guidance for integrating these tools into secure and compliant software pipelines.
Thanks for reading Compliance Left Shifted! Subscribe for free to receive new posts and support my work.
Traditional compliance methods rely on manual checklists and periodic audits, creating bottlenecks that slow the software release process. These processes also increase the risk of human error and make it difficult to adapt to fast-paced environments. By shifting compliance left—embedding it directly into development pipelines—we can:
Automate Compliance: Reduce manual intervention by enforcing policies programmatically.
Enhance Consistency: Ensure uniform application of policies across all projects and teams.
Accelerate Delivery: Integrate compliance into existing workflows to minimize delays.
Increase Transparency: Generate auditable evidence of compliance in real-time.
NIST SP 800-204D provides guidance for applying these principles to secure pipelines. It outlines best practices for building, verifying, and deploying software securely using automation tools. Witness, for example, embodies the principles of NIST SP 800-204D by enabling cryptographic attestations and automated policy enforcement.
Hadolint is an open-source Dockerfile linter that checks for inefficiencies, security vulnerabilities, and bad practices in container configurations. It flags issues like running as root or using floating image tags, helping developers produce more secure and efficient container images.
Witness, on the other hand, enforces policies as code by collecting cryptographic attestations and verifying that specific steps in a pipeline comply with defined rules. By integrating Hadolint and Witness into a CI/CD pipeline, we ensure compliance is automatic, continuous, and baked into the development process.
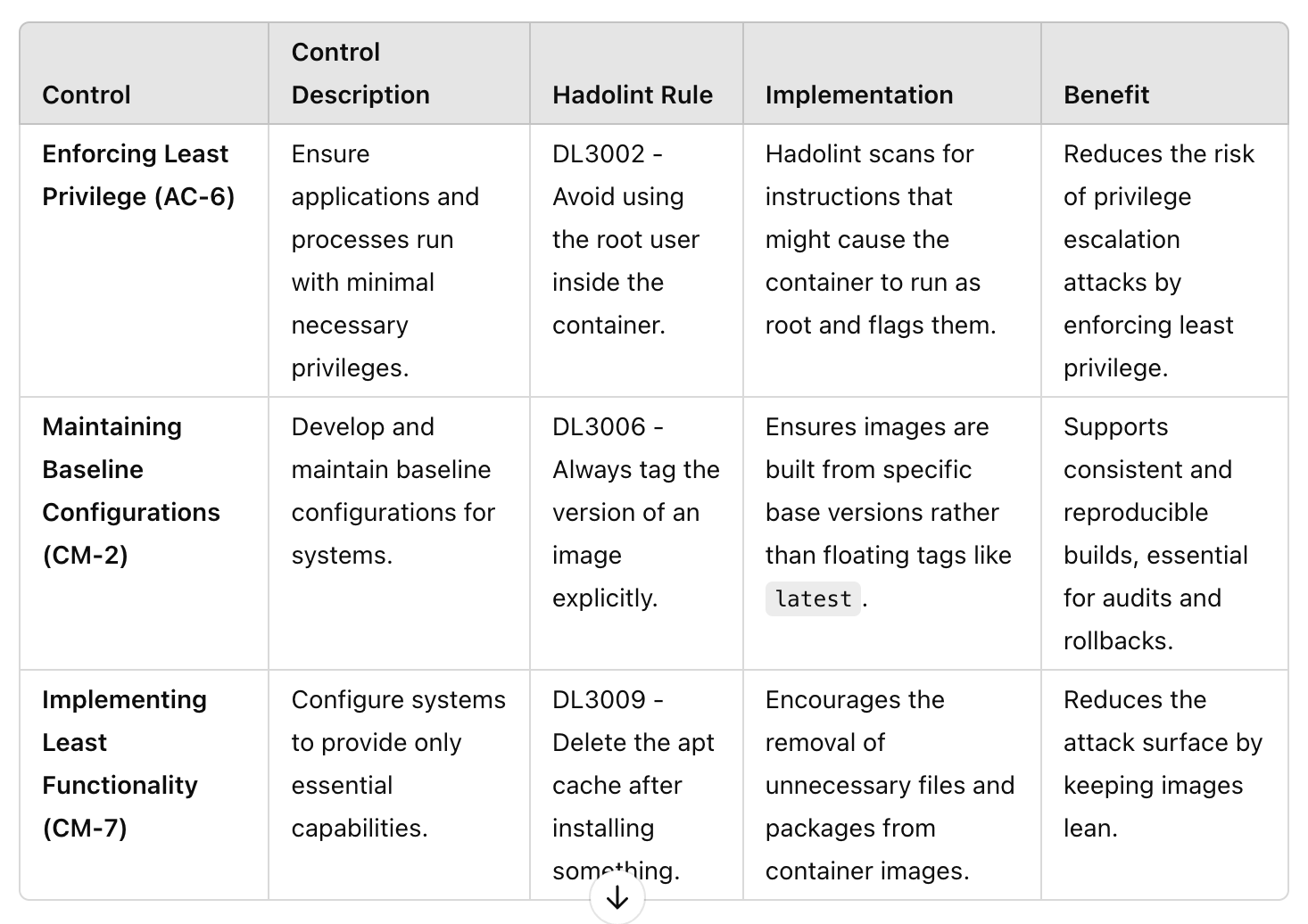
Hadolint’s linting rules map directly to several NIST SP 800-53 controls. Here’s how:
Enforcing Least Privilege (AC-6):
Control Description: Ensure applications and processes run with minimal necessary privileges.
Hadolint Rule: DL3002 - Avoid using the root user inside the container.
Implementation: Hadolint scans for instructions that might cause the container to run as root and flags them.
Benefit: Reduces the risk of privilege escalation attacks by enforcing least privilege.
Maintaining Baseline Configurations (CM-2):
Control Description: Develop and maintain baseline configurations for systems.
Hadolint Rule: DL3006 - Always tag the version of an image explicitly.
Implementation: Ensures images are built from specific base versions rather than floating tags like latest.
Benefit: Supports consistent and reproducible builds, essential for audits and rollbacks.
Implementing Least Functionality (CM-7):
Control Description: Configure systems to provide only essential capabilities.
Hadolint Rule: DL3009 - Delete the apt cache after installing something.
Implementation: Encourages the removal of unnecessary files and packages from container images.
Benefit: Reduces the attack surface by keeping images lean.
Witness allows us to go beyond linting by enforcing policies at every step of the pipeline. Let’s walk through how to implement a portion of the Witness policy for the lint step. See the full policy here
{
"steps": {
"lint": {
"name": "lint",
"attestations": [
{
"type": "https://witness.dev/attestations/command-run/v0.1",
"regopolicies": [
{
"name": "expected command",
"module": "cGFja2FnZSBjb21tYW5kcnVuLmNtZAoKZGVueVttc2ddIHsKCWlucHV0LmNtZCAhPSBbIi9iaW4vc2giLCAiLWMiLCAiaGFkb2xpbnQgLWYgc2FyaWYgRG9ja2VyZmlsZSA+IGhhZG9saW50LnNhcmlmIl0KCW1zZyA6PSAidW5leHBlY3RlZCBjbWQiCn0K"
}
]
}
]
}
}
}The module field contains Base64-encoded Rego code. Decoded, it looks like this:
package commandrun.cmd
deny[msg] {
input.cmd != ["/bin/sh", "-c", "hadolint --disable-ignore-pragma -f sarif Dockerfile > hadolint.sarif"]
msg := "unexpected cmd"
}This Rego policy enforces that the exact command /bin/sh -c "hadolint -f sarif --disable-ignore-pragma Dockerfile > hadolint.sarif" is executed in the lint step.
If the command differs: The pipeline denies the step and logs the message “unexpected cmd.”
Why it matters: This ensures no command injection or policy bypass can occur, maintaining strict control over the configuration of the security tool, ensuring compliance for every artifact, every time.
Witness Policies and NIST SP 800-204D
NIST SP 800-204D emphasizes automation and cryptographic assurance in securing software pipelines. Witness implements these principles by:
Automating Policy Enforcement: Ensures policies are enforced consistently and automatically.
Providing Cryptographic Assurance: Verifies the authenticity of each attestation collected during the pipeline.
Enabling Continuous Compliance: Tracks compliance at every step of the pipeline in real time.
Here’s an example of integrating Hadolint and Witness into a GitHub Actions workflow using the Witness Run GitHub action:
lint:
uses: testifysec/witness-run-action/.github/workflows/witness.yml@reusable-workflow
with:
pull_request: ${{ github.event_name == 'pull_request' }}
step: lint
pre-command-attestations: "git github environment"
attestations: "git github environment"
archivista-server: "https://platform.testifysec.dev"
pre-command: |
curl -sSfL https://github.com/hadolint/hadolint/releases/download/v2.12.0/hadolint-Linux-x86_64 -o /usr/local/bin/hadolint && \
chmod +x /usr/local/bin/hadolint
command: hadolint -f sarif --disable-ignore-pragma Dockerfile \
> hadolint.sarif
artifact-upload-name: hadolint.sarif
artifact-upload-path: hadolint.sarifExact Command Enforcement: Prevents unauthorized or unexpected commands.
Audit Trails: Automatically collects evidence for compliance audits.
Automation: Reduces manual oversight by integrating compliance checks into pipelines.
Alignment with NIST SP 800-204D: Implements secure pipeline practices outlined in the framework.
Now that we have both the policy created and the attestation for the final artifact, we can validate that the artifact went through the correct process. We pass in the key material, the signed policy, and the artifact's location we want to verify. In this case, we use the TestifySec platform to store and serve the attestations.
witness verify -p policy-signed.json -k swfpublic.pem -f /tmp/image.tar --enable-archivista --archivista-server https://platform.testifysec.dev -l debugWhen this command is run, it will generate an SLSA Verification Summary Attestation (VSA) with a pass or fail status. The attestation will include references to the policy and the evidence used to evaluate the policy. If the verification fails Witness will output detailed information to help debug the cause
By integrating Hadolint and Witness into our CI/CD pipelines, we shift compliance left—embedding it directly into the development process. This approach:
Automates compliance, reducing manual intervention.
Enhances security by preventing misconfigurations and unauthorized changes.
Provides real-time evidence of compliance, simplifying audits and regulatory reviews.
This series is just getting started. Next, we’ll explore how Witness policies can enforce other NIST SP 800-53 controls and dive deeper into the principles of NIST SP 800-204D. If you’re interested in trying Witness, check out this step-by-step guide.
References:
Witness: https://witness.dev
SWF Repo (Full Example): https://github.com/testifysec/swf
Getting Started with Witness: https://testifysec.com/blog/attestations-with-witness
Hadolint: https://github.com/hadolint/hadolint
NIST SP 800-53: https://csrc.nist.gov/publications/detail/sp/800-53/rev-5/final
NIST SP 800-204D: https://csrc.nist.gov/publications/detail/sp/800-204d/final
Thanks for reading Compliance Left Shifted! Subscribe for free to receive new posts and support my work.
Developers dislike the "shift left" approach. It's not because they hate security but because they want to ship code. We are asking a lot of developers, and it's okay; we like a challenge and we get paid a lot. What we would like is a CI system that doesn't keep us from merging perfectly good code. Imagine wrapping up an issue on a Friday afternoon after a grueling crunch to deliver a feature, only to have your CI fail. It's frustrating, and sometimes, we're even told to disable tests just to get code out the door, cough Volkswagen cough.

Over the past seven years, I've been deep in the trenches of DevSecOps. The default playbook has been to halt developers at every security or test failure. On the surface, stopping production when we detect a quality issue seems logical, it's a principle borrowed from lean manufacturing and the Toyota Production System. The idea is to ensure quality and reduce rework by catching issues early. But maybe it's time we rethink this. Maybe treating digital assets the same way we treat durable goods isn't the best approach.
Thanks for reading Compliance Left Shifted! Subscribe for free to receive new posts and support my work.
Rework is costly, in time and materials with physical goods or when you have slow distribution, such as manually updating a ROM on a fleet of vehicles. However, does stopping work make sense when deploying to an online system with incremental rollouts?
As a founder of a software company, I need the code to deliver value as quickly as possible, it is the only way we will survive. It makes sense to slow deployments for costly systems to deploy to—think embedded systems, packaged software, and physical goods. However, as the deployment cost decreases, the need to stop production to fix quality issues also decreases. In fact, with fast systems, as long as we provide visibility to the developers, prevent non-compliant systems from deploying, and implement some sort of incremental rollout (please at least one machine), we should never block CI. The only block on CI should be for human code review and build failure.
Products such as GitHub, GitLab, CircleCI, Jenkins and friends are amazing at what they do. I have used most of them in anger, they all do pretty much the same thing. Orchestrate software builds, deployments, and testing. However, they were are built before the world woke up to Software Supply Chain attacks and the Log4Shell CVE. It was a different world back then. Most organizations didn’t see open source as a security risk, there was no body of knowledge around securing developer environments and the impact a break there could have.
This forced us DevOps engineers to shove test after test into the pipeline. Some wizards could craft some efficient pipelines, but they all looked something like this.
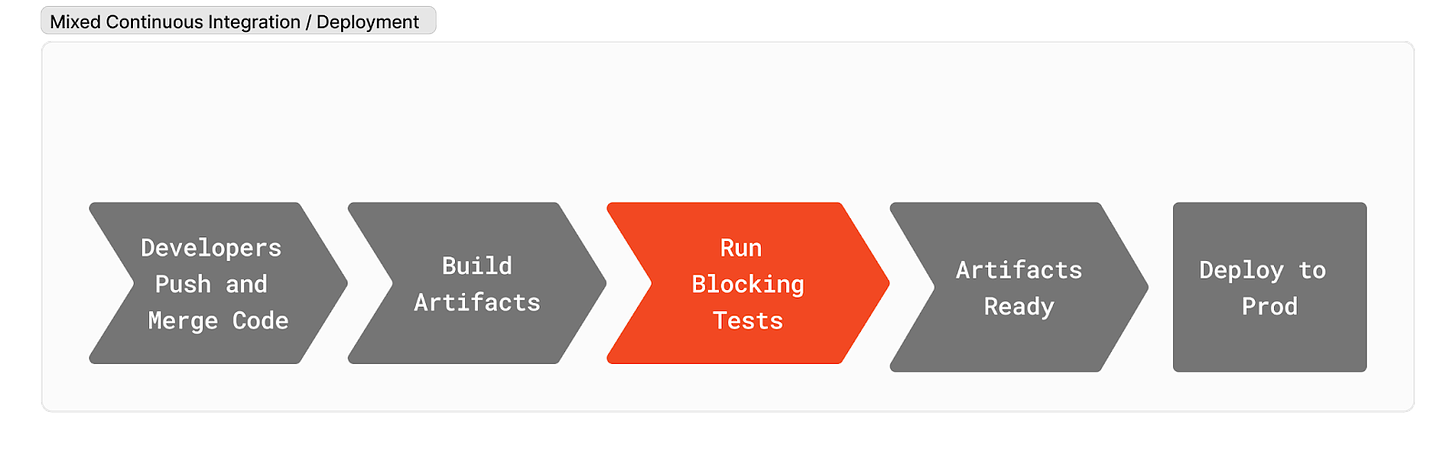
Most organizations block CI on test failure. Stopping code from delivering value.
A single pipeline, or set of pipelines, glues together. If everything magically passes you are granted access to production infrastructure. The problem is that pipelines break all of the time, and it forces anti-patterns such as combining CI and CD into a single pipeline (aside: see this amazing talk by Adobe and AutoDesk on the benefits on separating these two concerns) If you are blocking on high/critical CVEs the dev may have to stop feature work for a CVE that doesn’t even matter. We do all of this in the name of security and compliance.
The thing is, when a CEO has to weigh compliance, security, and revenue, revenue always wins. If complying costs us revenue, there better be a clear payoff. As a result, developers are incentivized to meet tight deadlines by bypassing or disabling testing to ship. Security often takes a backseat, creating a cycle where vulnerabilities slip through unnoticed. While this may provide short-term gains in delivery speed, it exposes organizations to long-term risks like software supply chain attacks or compliance penalties. The perfect system we build falls apart for all but the most regulated industries.
The alternative is creating very restrictive pipeline templates that are forced to execute cleany before software is “allowed” to deliver value.
The issue lies in how traditional DevSecOps systems enforce security. They inadvertently create bottlenecks by placing tests as rigid gatekeepers in the CI/CD pipeline. When a pipeline breaks, progress halts, and developers lose valuable time investigating false positives or minor issues. In many cases, the CVEs being flagged might not even be exploitable in the application's context, yet they block critical deployments.
This "all-or-nothing" approach to testing frustrates developers and weakens trust in the tools. Instead of empowering teams to deliver secure, high-quality software, it creates an adversarial relationship between security and development teams.
I am writing my first draft of this post on a flight back from KubeCon. KubeCon draws over 10,000 platform engineering enthusiasts twice yearly. If you want to understand how to build better platforms, KubeCon is the place to go.
You may have seen my article about the inversion in the DORA metrics' "change failure rate." According to DORA theory, high performers (deploying once a day) should have a lower "change failure rate" than those that only deploy once per week. The idea is that organizations that are organized enough to deploy frequently have fewer failures.
DORA metrics provide a framework for measuring software delivery performance, helping organizations align development speed with reliability and quality.
Deployment Frequency: How often an organization successfully releases to production.
Lead Time for Changes: Time from code committed to code running in production.
Change Failure Rate: Percentage of deployments causing a failure in production.
Time to Restore Service: Time taken to recover from a production failure.
Key Insight:
High-performing teams excel in these metrics, driving improved business outcomes such as profitability, productivity, and customer satisfaction. They ship code faster and more reliably, with fewer failures, showcasing the balance between speed and quality.
On my first day, at the first talk I attended at the co-located startup fest, I had the luck of sitting right next to Lucy Sweet. I had never met Lucy before, but I looked at her badge, it said Uber. Uber is probably the best company at CI/CD. Uber never goes down, and they deploy 34,000 times a week worldwide. They are the definition of a DORA elite performer. My guess is that their developers are not encouraged to disable or bypass tests.
I asked her why this inversion is not happening with elite performers such as Uber. I don't think I have ever seen somebody so excited to tell their story.

Uber takes a different approach to security. Instead of creating pipelines that are 15 steps long and fail 50% of the time due to flakiness, they defer the policy decision to the CD system. This allows developers to continue to push, merge, and review code while allowing the platform team to decide if the workload is safe to deploy - and providing feedback in the form of induced friction.

Uber uses incremental rollouts on each of their 34,000 deployments a week. Workloads build up trust over time and, combined with provenance data from tests against the codebase, classify the workload ranging from "unsecured" to "uber-secure." Workloads that are classified as uber-secure have the fastest rollout policy. They reduce the friction between the developer and production as much as possible. However, workloads that do not pass some of the required security tests are given the most restrictive rollout policy. Uber created a system that incentivizes good behavior.
“Every test case is automatically registered in our datastore on land. Analytics on historical pass rate, common failure reasons, and ownership information are all available to developers who can track the stability of their tests over time. Common failures are aggregated so that they can be investigated more easily”. - https://www.uber.com/en-DK/blog/shifting-e2e-testing-left
Uber's approach to continuous deployment shows us what's possible when we rethink traditional practices. Uber empowers developers to push, merge, and review code without unnecessary blockers by deferring policy decisions to the CD system and using incremental rollouts. This strategy lets workloads build trust over time, classifying them based on provenance data and tests against the codebase.

Shifting the policy enforcement point from CI to CD had a profound impact on Uber's engineering culture. Instead of beating developers over the head with a stick for not passing CI—often due to flakiness or issues beyond their control—Uber has gamified security and reliability engineering. Advancing security from "unsecured" to "uber-secure" feels rewarding; developers don't want to be at level one for security—they aim to be the best. This approach incentivizes good behavior and fosters a positive engineering culture.
However, until tools like Witness and Archivista were available, organizations didn't have the means to defer policy enforcement effectively. Pipeline blocks have traditionally been the only way to ensure quality, forcing developers to address issues before code could proceed. By moving policy enforcement to the CD stage, we provide visibility and maintain high standards without grinding the development process to a halt.
Pipeline blocks are with good intentions. Previously, tracking the provenance of these CI steps has not been possible using off-the-shelf tools. You needed to build custom systems to do this. Uber's model flips the script on the traditional "shift left" mentality. Instead of bogging down the CI pipeline with endless checks that fail half the time due to flakiness, they allow the platform team to make deployment decisions based on the workload's security posture. This doesn't mean security is an afterthought; it's integrated into the deployment process in a way that doesn't impede progress.

It's time we stop treating digital assets like durable goods. Rework is tough with physical products, but in software, especially with systems that support rollouts, we can afford to be more flexible. Blocking CI for every test or security failure might not be the best approach anymore. Instead, we should focus on providing visibility to developers and preventing non-compliant systems from deploying without grinding the entire process to a halt or encouraging bad behavior.
What are Witness and Archivista? Witness and Archivista are tools that enable organizations to gather and store compliance evidence throughout the development and deployment process. Witness captures provenance data, while Archivista stores this data, allowing teams to defer policy enforcement from earlier CI stages to later in the CD pipeline, ensuring compliance without halting development progress.
Autodesk has embraced Witness and Archivista to defer policy decisions until the CD phase. This strategy allows product development to move forward without hitting compliance roadblocks, ensuring only compliant artifacts make it into production. By generating Trusted Telemetry with Witness and storing it in Archivista, they gain deep insights into the compliance and security status of every artifact ever built. Patterns like this have even helped them achieve FedRAMP ATO
.

Autodesk leverages the CNCF in-toto project's Witness CLI tool, following recommendations in NIST 800-204D, to generate attestations throughout their SDLC. By instrumenting CI steps, developers can customize their pipelines while still using core libraries that inject platform tooling to produce cryptographically signed metadata. These attestations are stored in Archivista, allowing Autodesk to query and inspect metadata via a graph API. This setup enables them to trace artifacts back to their source, ensuring integrity and facilitating policy decisions during the CD phase. For instance, if a suspicious binary is discovered, they can use the stored attestations to determine if it was built on their systems and identify the associated change request.
If this resonates with you, it's worth considering how we can apply these insights to your development and deployment processes. By rethinking how you handle CI/CD pipelines and security checks, you can reduce friction between developers and production, allowing for faster value delivery without compromising security.
Adopting strategies like Uber's can help reduce engineering and compliance costs. It enables teams to maintain high-security standards while delivering features and updates more efficiently. We are working on problems like these at TestifySec and the in-toto community. Read our blog, join us on CNCF Slack, or let us know if you would like to see what a compliance platform that developers love looks like.
Thanks for reading Compliance Left Shifted! Subscribe for free to receive new posts and support my work.
Uber. (n.d.). Continuous deployment for large monorepos. Uber Engineering Blog. Retrieved from https://www.uber.com/en-AU/blog/continuous-deployment/
Uber. (n.d.). Shifting E2E testing left at Uber. Uber Engineering Blog. Retrieved from https://www.uber.com/en-DK/blog/shifting-e2e-testing-left/
Toyota. (n.d.). Toyota Production System. Toyota Global. Retrieved from https://global.toyota/en/company/vision-and-philosophy/production-system/
DevSecOps has left compliance in the dust. Developers can now move faster than their code can be evaluated for risk, by several orders of magnitude. Compliance teams often lack the engineering expertise or the tools needed to keep up with the pace of development. Meanwhile, developers don’t always understand the business value compliance brings—revenue often requires compliance. It’s frustrating, and many CISOs are forced to make a difficult choice: slow down product development to the speed of compliance or accept the risk. Through incidents like SolarWinds and CrowdStrike, we've seen that accepting risk and blindly trusting developers can have real consequences.

Compliance, like building codes, exists to prevent incidents. When developers move ahead without compliance guardrails, it’s like building a house without knowing the local building code. You dig the foundation, frame the house, add the roof, and install utilities—all by industry best practices. But just as the house is ready for handoff, you discover it’s in a floodplain and needs to be built on stilts. You might build something strong and efficient, but missing critical information can compromise everything.
Thanks for reading Compliance Left Shifted! Subscribe for free to receive new posts and support my work.
This is the current state of software development in high-compliance environments. After transitioning from the military to the civilian world, my first job as a software developer was contracting for the Joint Special Operations Command. It was my dream job—I had tried, unsuccessfully, to earn my “long tab” as a US Army Special Forces member, but after two years in the qualification course, I knew that life wasn’t for me. Sometimes, though, life gives you lemons, and other times you get lucky. My luck was finding work with a tier-one organization, fighting terrorism with code.
It was around 2017, and the fight against ISIS was in full swing. I was tasked with deploying and adapting one of my team’s applications for a partner network. We needed to change the data classification model to support non-US countries. The changes were straightforward, tested, and approved by our authorizing official.
The next step was deploying the application to the partner network. The mission was critical, and urgency was high—so high that I was sent to Jordan the week before Christmas. I was on board, though my wife wasn’t thrilled. We’d just welcomed our first daughter, and she needed me. But my country needed me, too, and the mission and our financial situation won out.
Once I got to Jordan, I began coordinating the application install—but was stopped dead in my tracks. We didn’t have authorization to deploy on the parner network. It was a different commander from a different country, and our authorization package wasn’t compatible.

This was completely on the compliance team. As a developer, I had no idea what the compliance requirements were. Looking back, we did everything right: we used the right encryption, TLS was in place, and our AuthN/AuthZ and data security model was top-notch. But it didn’t matter. Our compliance team hadn’t generated or communicated any compliance requirements. I didn’t understand NIST 800-53 or that our software and development process had control validation requirements.
While this might sound like an exceptional failure story, it’s a pattern across organizations, regardless of their glamour or bureaucracy, if they have compliance requirements. Take FedRAMP, for example. FedRAMP is an excellent program—probably one of the most successful tech programs in the US government. It connects innovators with Federal missions and generates billions in revenue for companies with that stamp of approval.
However, compliance comes at a high cost. Every new feature or AI model a company adds now needs FedRAMP authorization. The current compliance processes and technologies can’t keep up with development. The companies that the government wants in the FedRAMP marketplace are the same ones trying to ship updates 100x daily to remain competitive. This disconnect is massive, with modern compliance processes barely able to produce an evaluation once a month.
According to a CloudBees survey 64% of executives say their teams see compliance as the “department of slow.” Further, C-suite leaders report spending over 37 days annually on compliance audits—time that could be better spent on innovation.
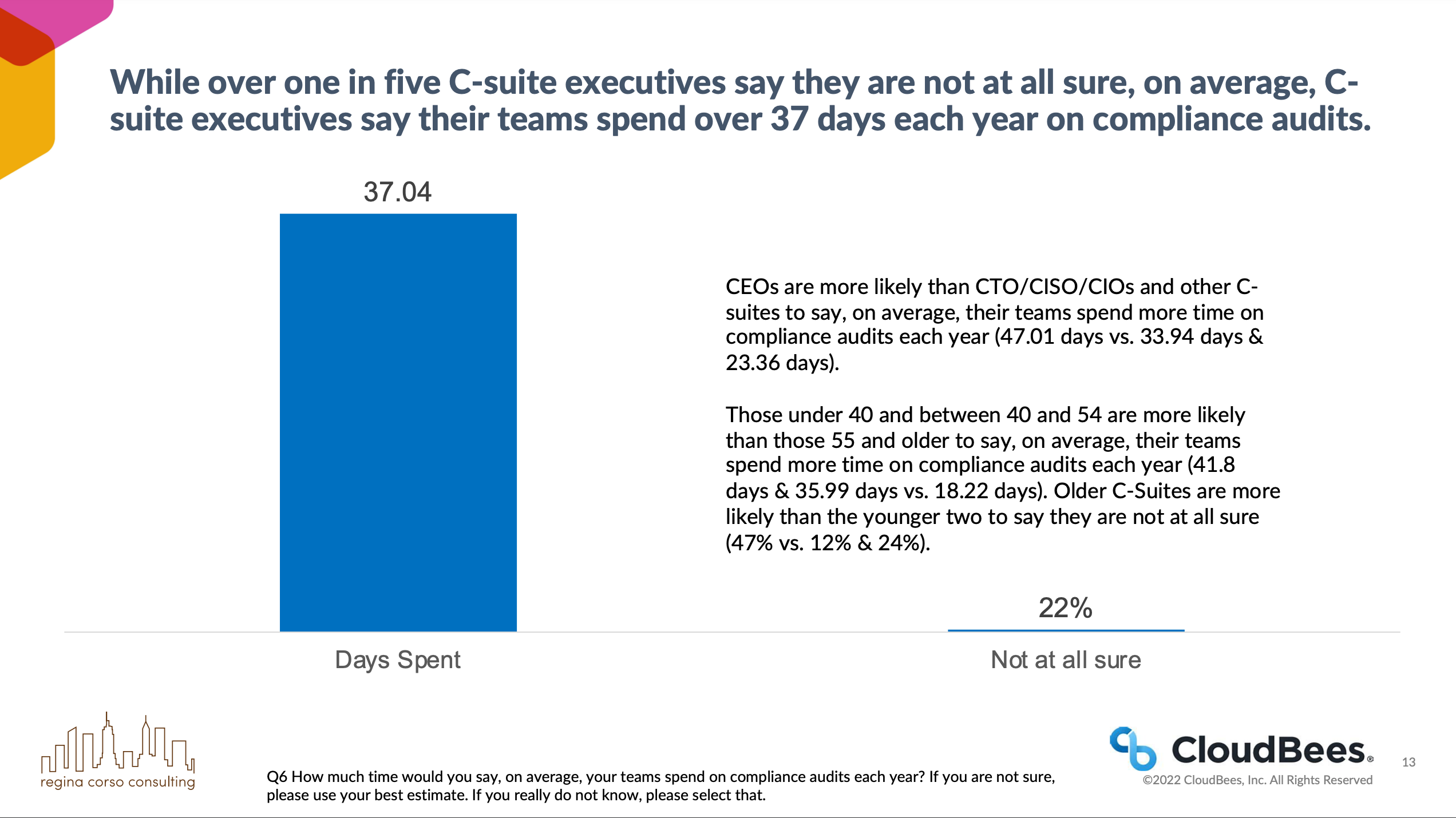
Let’s return to our story. The compliance team failed to understand and communicate the requirements of this new system, which resulted in the software development team's never-realized business goals. The code we spent months developing could never deliver value because it wasn’t compliant. We could have saved time, money, and lives by shifting compliance checks earlier in development.
So, can we have our cake and eat it too? Can organizations foster a culture of innovation and continuous delivery—the values driving commercial success—while competing in the Federal market, which prizes compliance over features? The answer is yes, and it’s our vision at TestifySec. Let me know if you’d like a sneak peek at what we’re building. It’s still raw but has already proven to accelerate time-to-market for compliance frameworks like FedRAMP with users such as AutoDesk.
Thanks for reading Compliance Left Shifted! Subscribe for free to receive new posts and support my work.
DevSecOps promised us automation, speed, and security woven directly into development. But we're hitting clear limits, especially in terms of visibility and traceability. These are critical for automating compliance controls on developer actions. With "Shift Left" and DevSecOps, developers now have the ability to change production with every commit—potentially hundreds of times a day. Meanwhile, compliance teams, at best, manage monthly reporting in most organizations.

Thanks for reading Cole’s Substack! Subscribe for free to receive new posts and support my work.
There's a huge disconnect between compliance teams and development teams. Developers will say compliance moves too slow. Compliance needs to figure out how to move faster. But as a developer by trade, I have to ask: What have we done to make it easier for compliance teams to understand the state of our software?
Compliance teams deliver value by allowing products to enter new markets. SOC 2, PCI DSS, HITRUST, and FedRAMP are all gateways to additional users of our software. Cash aside, isn't that what we want most? We want people to derive actual, real value from our software.
So how does this work in practice? With "Shift Left," many high-performing organizations have integrated security checks into their development pipelines. If your dependency has a CVE (Common Vulnerabilities and Exposures), no merge for you.
And this is why developers hate security. We're focused on solving business problems—pushing code, pulling open-source packages. We have a solution and want to push our code, but we're blocked. One of the packages we pulled in to solve the problem, deliver the feature, includes a critical CVE, and there's no fix. But as the developer, I know this CVE is 100% out of scope. It doesn't matter, though. The compliance team will pick up the vulnerability and initiate a mountain of paperwork, if you don’t know what a POA&M is, consider yourself lucky.

Let's flip the script and see it from the compliance team's perspective. FedRAMP is a huge market. You know this because your CRO (Chief Revenue Officer) has had it in their slide deck for the past three years. The task seems insurmountable. You're dealing with 45 microservices, 12 cloud services, a development team of over 300 spread across 16 time zones. You have six months to validate 180 NIST Controls across an unknown number of systems.
The diversity of systems and teams makes maintaining consistent governance and security practices a daunting task. The compliance team is under immense pressure to ensure everything meets regulatory standards, and any misstep could have significant repercussions.
There's a massive disconnect here. Developers see compliance as a blocker, while compliance teams are overwhelmed trying to rein in rapid development cycles that outpace their ability to monitor and report.
76% of C-suite executives say compliance challenges limit their ability to innovate. Integrating compliance into development could bridge this gap without stifling creativity.
My co-founder and I developed Witness and Archivista to address this issue and donated them to the CNCF in-toto project. These tools have helped security and compliance teams at organizations such as Autodesk and Farmers Insurance keep pace with developers, enabling them to meet compliance requirements without slowing down development cycles.
As a developer, I believe we need to take some responsibility. What have we done to make it easier for compliance teams? We need to ensure that our processes are transparent and that we provide the necessary visibility.

So, how do we fix this? We need to shift compliance left—just like we did with security. This doesn't mean piling more work onto developers. Instead, it's about integrating compliance checks into our pipelines in a way that doesn't disrupt our workflows.
Imagine if compliance evidence was automatically collected as part of our development process. No more chasing down developers for security scans, test results, or evidence of regulatory compliance. The data would be there, readily available, and up-to-date.
We can achieve this by:
Implementing Observability into the SDLC: By observing developer actions and mapping them to compliance controls, we can understand compliance without impacting velocity.
Automating Compliance Tasks: Tools can automatically collect necessary evidence, reducing manual effort and errors.
Enhancing Communication: Improving lines and methods of communication between developers and compliance teams can bridge the gap.
By adopting trusted telemetry, we can collect data about what's happening in our development processes securely and reliably. This data serves as the evidence needed for compliance without placing additional burdens on developers.
Developers can focus on coding, knowing that compliance evidence is being collected transparently in the background.
Compliance teams get real-time visibility into the development process, reducing the need for manual reporting and endless paperwork.
As developers, we need to take the initiative here; we are the experts in our systems, and compliance is trying to do its job to protect the business from risk and help expand the use of your software into new markets. Let's:
Adopt Tools and Practices that integrate compliance into our workflows without adding friction. I’ll make a note to write an article about the open-source automated governance toolsets that are out there.
Collaborate with Compliance Teams to understand their needs and challenges.
Promote Transparency in our processes to make it easier for compliance teams to do their job.
Compliance teams, on the other hand, need to embrace automation and integration. By leveraging technologies that provide observability and automation, they can keep up with the pace of development and reduce the burden on both sides.
Shifting compliance left isn't about shifting the burden; it's about building a collaborative environment where compliance and development work hand-in-hand. By integrating compliance into our development pipelines, we can reduce friction, speed up time to market, and ensure that our software not only solves business problems but also meets the necessary regulatory standards.
After all, we all want the same thing—to deliver valuable, secure, and compliant software to our users.
Thanks for reading Cole’s Substack! Subscribe for free to receive new posts and support my work.